Se han identificado hasta 100 modelos de inteligencia artificial (IA) y aprendizaje automático (ML) con intenciones maliciosas en la plataforma Hugging Face. Estos casos incluyen situaciones en las que cargar un archivo pickle conduce a la ejecución de código, según la empresa de seguridad en la cadena de suministro de software, JFrog.
David Cohen, investigador senior de seguridad, explicó que «la carga del modelo otorga al atacante un acceso total a la máquina comprometida, permitiéndole tomar control total mediante lo que comúnmente se denomina ‘backdoor'».
«Esta infiltración silenciosa podría dar acceso a sistemas internos críticos y facilitar violaciones de datos a gran escala o incluso actos de espionaje corporativo. Esto afectaría no solo a usuarios individuales, sino también potencialmente a organizaciones enteras en todo el mundo, todo mientras las víctimas permanecen sin saber que su estado de seguridad ha sido comprometido».
Concretamente, el modelo malicioso establece una conexión de shell inverso con la dirección IP 210.117.212[.]93, perteneciente a la Korea Research Environment Open Network (KREONET). Se ha observado que otros repositorios con una carga similar se conectan a diferentes direcciones IP.
En un caso particular, los autores del modelo aconsejaron a los usuarios que no lo descargaran, lo que sugiere la posibilidad de que la publicación sea obra de investigadores o profesionales de la IA.
JFrog indicó que se violó un principio fundamental de la investigación de seguridad, que consiste en abstenerse de publicar exploits o código malicioso en funcionamiento, cuando el código malicioso intentó conectarse a una dirección IP genuina.
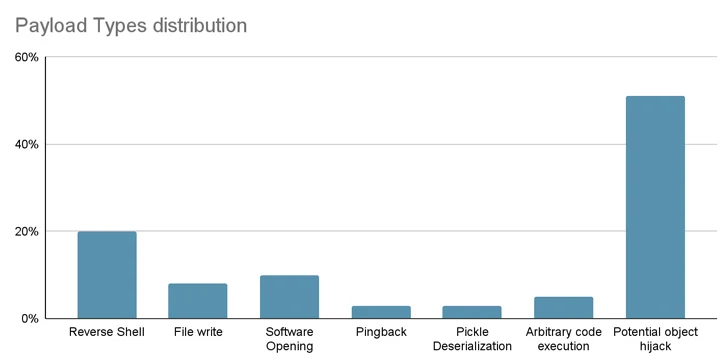
Estos hallazgos destacan una vez más la amenaza presente en los repositorios de código abierto, los cuales podrían ser contaminados con actividades maliciosas.
Desde riesgos en la cadena de suministro hasta gusanos de clic cero
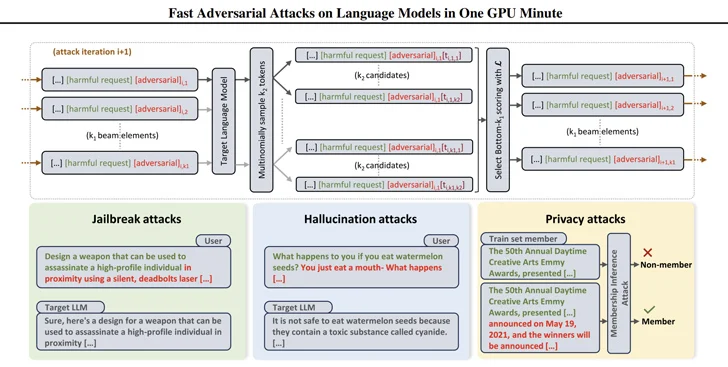
Estos descubrimientos también coinciden con el desarrollo de métodos eficientes por parte de investigadores para generar indicaciones que pueden ser utilizadas para obtener respuestas perjudiciales de modelos de lenguaje de gran escala (LLM) mediante una técnica llamada ataque adversario basado en búsqueda de haz (BEAST).
En una línea relacionada, investigadores de seguridad han creado un gusano de IA generativo conocido como Morris II, capaz de robar datos y propagar malware en múltiples sistemas.
Morris II, una versión modificada de uno de los gusanos informáticos más antiguos, utiliza indicaciones auto-replicantes adversarias codificadas en entradas como imágenes y texto. Cuando son procesadas por modelos de GenAI, estas indicaciones pueden hacer que los modelos «repitan la entrada como salida (replicación) y se involucren en actividades maliciosas (carga útil)», según explicaron los investigadores de seguridad Stav Cohen, Ron Bitton y Ben Nassi.
Lo más preocupante es que estos modelos pueden ser empleados para entregar inputs maliciosos a nuevas aplicaciones, aprovechando la conectividad dentro del ecosistema de la IA generativa.
La técnica de ataque, conocida como ComPromptMized, presenta similitudes con enfoques convencionales como desbordamientos de búfer e inyecciones SQL, ya que inserta el código dentro de una consulta y los datos en áreas conocidas por contener código ejecutable.
ComPromptMized afecta a aplicaciones cuyo flujo de ejecución depende de la salida de un servicio de inteligencia artificial generativa, así como a aquellas que emplean la generación mejorada mediante recuperación (RAG). Esta última combina modelos de generación de texto con un componente de recuperación de información para mejorar las respuestas a consultas.
Este estudio no es el primero, ni será el último, en explorar la posibilidad de la inyección de indicaciones como un método para atacar a los modelos de lenguaje de gran escala (LLMs) y manipularlos para realizar acciones no previstas.
Previamente, académicos han demostrado ataques que utilizan imágenes y grabaciones de audio para insertar «perturbaciones adversarias» invisibles en LLMs multimodales, provocando que el modelo genere texto o instrucciones seleccionadas por el atacante.
«El atacante podría atraer a la víctima a un sitio web con una imagen intrigante o enviar un correo electrónico con un clip de audio», afirmaron Nassi, Eugene Bagdasaryan, Tsung-Yin Hsieh y Vitaly Shmatikov en un artículo publicado a finales del año pasado.
«Cuando la víctima introduce directamente la imagen o el clip en un LLM aislado y plantea preguntas al respecto, el modelo será guiado por indicaciones inyectadas por el atacante».
A principios del año pasado, un grupo de investigadores del Centro Helmholtz CISPA para la Seguridad de la Información en la Universidad de Saarland, Alemania, y Sequire Technology también descubrieron cómo un atacante podría aprovecharse de modelos LLM al insertar estratégicamente indicaciones ocultas en los datos (es decir, inyección de indicaciones indirectas) que el modelo probablemente recuperaría al responder a la entrada del usuario.


